第21回シェル芸勉強会へ遠隔参加
バレンタインデーを明日に控え、皆様いかがお過ごしでしょうか?そんな中あいにくの雨天にも関わらず、第21回シェル芸勉強会の福岡サテライト会場を開設させていただいました。福岡サテライトは開催5回目です。素晴らしい会場をご提供いただき、会場ご提供者と会場管理者の方ありがとうございます。そしてまた写真撮るの忘れました・・・
問題作成と解説の上田さん、ありがとうございます。参加者の皆様お疲れ様でした。
勉強会の情報
問題と解答
勉強会主催者の上田さんが公開されているページをご覧ください。
会場の案内など
イベント案内はこちら。
福岡サテライト会場案内
https://atnd.org/events/74328atnd.org
大阪サテライト会場の案内
5f01b3bc1d81c1fae2378cdc89.doorkeeper.jp
ちなみに大阪は今回も寺シェル芸で徳をつまれたようです。
大阪サテライト会場です!
— くんすと (@kunst1080) 2016年2月13日
※入り口は裏手ですのでお間違えなきよう #シエル芸 pic.twitter.com/lAuOSNAJnr
— くんすと (@kunst1080) 2016年2月13日
東京本家勉強会の案内
Togetterまとめ
勉強会当日のTwitterまとめはこちら。ハッシュタグは#シェル芸。
勉強会レポート
午前の部について
午前中の部は自宅から遠隔参加しました。 午前の部は正規表現の濃いお話と、シェルがコマンドを実行するまでに何が起きているか?という内容で、どちらもかなり興味深かったです。
正規表現の濃いお話
www.slideshare.net
午後の部
今回は新しく学生さんがいらっしゃったり、また遠くは大分県日田から来られた方もいらっしゃったりでした。 また、ユーザ企業さんの情報部門な方もいらっしゃいました。参加者は全員で8人でした。
イントロスライドを少し話をした後、勉強会のライブストリームに突入しました。
やっつけイントロスライド
www.slideshare.net
今回の問題は、出題者上田さん著書「シェルプログラミング実用テクニック」の本を読んでいれば解けるはず!ということですが、、、
私が考えた解答例を記載いたします。環境はmacOSを使ってました。
Q1
pdfファイルからテキストを抜き出す。とりあえずpdftotextコマンドとか使えばいいのでしょうか?
$ pdftotext bba.pdf
Syntax Warning: Invalid Font Weight
あれ?何かエラーが出ちゃった??と思ってたら、
$ ls -l
total 40
-rw-r--r--+ 1 tashiro staff 13534 2 13 14:13 bba.pdf
-rw-r--r--+ 1 tashiro staff 61 2 13 23:51 bba.txt
$ cat bba.txt
群馬のシャブばばあ
hoge.txt[2016/02/09 22:30:32]
テキストファイルが出来ていました。エラー出力を抑制するには-qオプションを使い、標準出力に出すにはファイル名に-を使えばいいらしいです。
$ pdftotext -q bba.pdf -
群馬のシャブばばあ
hoge.txt[2016/02/09 22:30:32]
あとlessで見るといいという話もあったが、lessopenの設定とかが必要みたいですね。時間がなかったので詳しく調べられていません。
Q2
Shift JIS(cp932)の固定長データの処理の問題。
データをざっと見て、35バイト毎に区切れば良さそうかな?と思いましたが、下記のようにすると端末上ではへんてこりんな表示になってしまいました。
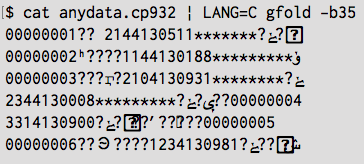
しかし表示が乱れているだけだったようで、そのままnkfに通せば良かったようです。半角カナをそのまま出力する-xを忘れてました、、
$ cat anydata.cp932 | LANG=C gfold -b35 | nkf -wx
00000001ハナモゲギンコウ*******2144130511
00000002ハードバンク*********1144130188
00000003コドモギンコウ********2104130931
00000004ハタンギンコウ*********2344130008
00000005アンダーグラウンドギンコウ3314130900
00000006バミューダメンゼイギンコウ1234130981
追記
データの中身を確認する方法です。odコマンドとiconvを使えばこんな感じで確認可能です。 Shift-JISの半角カナが濁点も1バイトだったりするのがわかりやすいと思います。
$ LANG=ja_JP.SJIS od -t x1c anydata.cp932 | iconv -f CP932
0000000 30 30 30 30 30 30 30 31 ca c5 d3 b9 de b7 de dd
0 0 0 0 0 0 0 1 ハ ナ モ ケ ゙ キ ゙ ン
0000020 ba b3 2a 2a 2a 2a 2a 2a 2a 32 31 34 34 31 33 30
コ ウ * * * * * * * 2 1 4 4 1 3 0
0000040 35 31 31 30 30 30 30 30 30 30 32 ca b0 c4 de ca
5 1 1 0 0 0 0 0 0 0 2 ハ ー ト ゙ ハ
0000060 de dd b8 2a 2a 2a 2a 2a 2a 2a 2a 2a 31 31 34 34
゙ ン ク * * * * * * * * * 1 1 4 4
0000100 31 33 30 31 38 38 30 30 30 30 30 30 30 33 ba c4
1 3 0 1 8 8 0 0 0 0 0 0 0 3 コ ト
0000120 de d3 b7 de dd ba b3 2a 2a 2a 2a 2a 2a 2a 2a 32
゙ モ キ ゙ ン コ ウ * * * * * * * * 2
0000140 31 30 34 31 33 30 39 33 31 30 30 30 30 30 30 30
1 0 4 1 3 0 9 3 1 0 0 0 0 0 0 0
0000160 34 ca c0 dd b7 de dd ba b3 2a 2a 2a 2a 2a 2a 2a
4 ハ タ ン キ ゙ ン コ ウ * * * * * * *
0000200 2a 2a 32 33 34 34 31 33 30 30 30 38 30 30 30 30
* * 2 3 4 4 1 3 0 0 0 8 0 0 0 0
0000220 30 30 30 35 b1 dd c0 de b0 b8 de d7 b3 dd c4 de
0 0 0 5 ア ン タ ゙ ー ク ゙ ラ ウ ン ト ゙
0000240 b7 de dd ba b3 33 33 31 34 31 33 30 39 30 30 30
キ ゙ ン コ ウ 3 3 1 4 1 3 0 9 0 0 0
0000260 30 30 30 30 30 30 36 ca de d0 ad b0 c0 de d2 dd
0 0 0 0 0 0 6 ハ ゙ ミ ュ ー タ ゙ メ ン
0000300 be de b2 b7 de dd ba b3 31 32 33 34 31 33 30 39
セ ゙ イ キ ゙ ン コ ウ 1 2 3 4 1 3 0 9
0000320 38 31 0d 0a 0d 0a
8 1 \r \n \r \n
0000326
Q3
ようやく普通な?問題。
いろいろやり方はありますが、会場で考えたのはこんなやり方です。
まずはseqとsedでやっつけな日付っぽいリストを作成します。やっつけ処理なので不正な日付も含まれるのに注意します。
$ seq -w 0101 1231 | sed 's/^/2016/'
20160101
20160102
20160103
20160104
20160105
....
20161227
20161228
20161229
20161230
20161231
次にGNU dateコマンドに渡す。-fオプションで読み込む日付のリストファイルを指定出来ますが、GNU dateだと-を指定すれば標準入力から読み込みます(フィルタモード)。不正な日付についてはエラーメッセージが出るので、エラー出力をリダイレクトで捨てます。
$ seq -w 0101 1231 | sed 's/^/2016/' | gdate -f - '+%Y%m%d %a' 2> /dev/null
20160101 金
20160102 土
20160103 日
20160104 月
20160105 火
....
20161227 火
20161228 水
20161229 木
20161230 金
20161231 土
あとはgrepで日曜日だけを抜き出して完成です。
$ seq -w 0101 1231 | sed 's/^/2016/' | gdate -f - '+%Y%m%d %a' 2> /dev/null | grep '日$'
20160103 日
20160110 日
20160117 日
20160124 日
20160131 日
....
20161127 日
20161204 日
20161211 日
20161218 日
20161225 日
追記
macOSやFreeBSDなどのBSD系OSに標準付属のdateコマンドは、標準入力から日付リストを受けることが出来ません(フィルタモードが無い)。 そこで下記のようにオプションを使うと、2016年1月1日から-vオプションで指定した日数後の日を表示します。
$ date -v+0d -j -f "%Y%m%d" 20160101 "+%Y%m%d %a"
20160101 金
$ date -v+1d -j -f "%Y%m%d" 20160101 "+%Y%m%d %a"
20160102 土
$ date -v+365d -j -f "%Y%m%d" 20160101 "+%Y%m%d %a"
20161231 土
上記の使い方をふまえて、下記のような回答が考えられます。ただしこのやり方は、dateコマンドが366回実行されるので、実行速度が遅くなります。
$ for i in {0..365}; do date -v+${i}d -j -f '%Y%m%d' 20160101 '+%Y%m%d %a'; done | grep '日$'
$ seq 0 365 | while read i; do date -v+${i}d -j -f '%Y%m%d' 20160101 '+%Y%m%d %a'; done | grep '日$'
$ seq 0 365 | xargs -I@ date -v+@d -j -f '%Y%m%d' 20160101 '+%Y%m%d %a' | grep '日$'
$ seq -f 'date -v+%gd -j -f "%%Y%%m%%d" 20160101 "+%%Y%%m%%d %%a"' 0 365 | sh | grep '日$'
$ seq 0 365 | sed 's/.*/date -v+&d -j -f "%Y%m%d" 20160101 "+%Y%m%d %a"/' | sh | grep '日$'
Q4
Tukubaiコマンドを解禁させてもらいました。
sortコマンドの使い方が重要なので、解説を行いながら解きました。
正統派?
catとsortで2つのファイルをまとめて並べ替えます。
sortコマンドの-sオプションで指定以外の列は並べ替えしないようにし、-k1,1オプションで1列目をキーに並べ替えます。
$ cat data newdata | sort -s -k1,1
001 あみだばばあ
002 砂かけばばあ
002 *******
003 ******
003 群馬のシャブばばあ
004 尾崎んちのババア
005 純愛ババア学園
あとはTukubaiのgetlastコマンドを使って、1列目をキーにして最後の列のみを取り出して完成です。
$ cat data newdata | sort -s -k1,1 | getlast 1 1
001 あみだばばあ
002 *******
003 群馬のシャブばばあ
004 尾崎んちのババア
005 純愛ババア学園
変則?
こちらはちょっと変則的なやり方。Tukubaiのloopjコマンドで横に連結します。
連結する際、データが無い部分は-dオプションでスペースを入れてしまうのがポイントです。
$ loopj -d' ' num=1 data newdata
001 あみだばばあ
002 砂かけばばあ *******
003 ****** 群馬のシャブばばあ
004 尾崎んちのババア
005 純愛ババア学園
あとはselfコマンドで1列目と最後の列を取り出して完成です。
$ loopj -d' ' num=1 data newdata | self 1 NF
001 あみだばばあ
002 *******
003 群馬のシャブばばあ
004 尾崎んちのババア
005 純愛ババア学園
Q5
テキストファイルの中に変なデータが混じっていることの確認方法。
今回はodコマンドの使い方を解説しました。私がよく使っているのは-t x1cオプションを使って表示するやり方です。
1オクテット毎に16進数とキャラクタ表示をします。バイトオーダーの影響も受けないので便利だと思います。
$ od -t x1c a.bash
0000000 ef bb bf 23 21 2f 62 69 6e 2f 62 61 73 68 0a 0a
357 273 277 # ! / b i n / b a s h \n \n
0000020 65 63 68 6f 20 48 65 6c 6c 0a
e c h o H e l l \n
0000032
efbbbfというバイナリ列がファイルの最初に混じってるのが確認出来ます。「BOM付きUTF-8」ということですね。
$ od -t x1c b.bash
0000000 23 21 2f 62 69 6e 2f 62 61 73 68 0a 0a 6c 73 20
# ! / b i n / b a s h \n \n l s
0000020 cb 9c 2f 0a
˜ ** / \n
0000024
それからチルダがcb 9cとなっていて、変なデータだということも確認出来ます。
余談ですが、MacやFreeBSDに付属するodコマンドは、マルチバイトの処理に対応しています。 日本語などが混じったデータでも、こんな感じでわかりやすく表示してくれて便利だと思います。
$ echo シェル芸勉強会 | od -t x1c
0000000 e3 82 b7 e3 82 a7 e3 83 ab e8 8a b8 e5 8b 89 e5
シ ** ** ェ ** ** ル ** ** 芸 ** ** 勉 ** ** 強
0000020 bc b7 e4 bc 9a 0a
** ** 会 ** ** \n
0000026
Q6
題意の理解に苦労しました。
要するに下記のようなテキスト処理をしろということでした。
a+h{5}(ho){10}[0-9]+
↑からこうじゃ↓
aa*hhhhhhohohohohohohohohoho[0-9][0-9]*
残念ながら解けませんでした。途中までは下記のように出たのですが。
$ cat extended | sed 's/a+/aa*/' | sed 's/\[0-9\]\+/[0-9][0-9]*/'
aa*h{5}(ho){10}[0-9][0-9]*
Q7
段落毎の文字数を数える問題。
段落毎ってのをどうするかがポイントになりそうです。 よくやるのは一度全部連結して都合のいい場所で改行する方法です。2つ目のsedコマンドは空行を削除しています。
$ cat text | tr -d '\n' | gsed 's/ /\n/g' | sed '/^$/d'
恥の多い生涯を送って来ました。
自分には、人間の生活というものが、見当つかないのです。自分は東北の田舎に生れましたので、汽車をはじめて見たのは、よほど大きくなってからでした。自分は停車場のブリッジを、上って、降りて、そうしてそれが線路をまたぎ越えるために造られたものだという事には全然気づかず、ただそれは停車場の構内を外国の遊戯場みたいに、複雑に楽しく、ハイカラにするためにのみ、設備せられてあるものだとばかり思っていました。しかも、かなり永い間そう思っていたのです。ブリッジの上ったり降りたりは、自分にはむしろ、ずいぶん垢抜けのした遊戯で、それは鉄道のサーヴィスの中でも、最も気のきいたサーヴィスの一つだと思っていたのですが、のちにそれはただ旅客が線路をまたぎ越えるための頗る実利的な階段に過ぎないのを発見して、にわかに興が覚めました。
また、自分は子供の頃、絵本で地下鉄道というものを見て、これもやはり、実利的な必要から案出せられたものではなく、地上の車に乗るよりは、地下の車に乗ったほうが風がわりで面白い遊びだから、とばかり思っていました。
あとは各行の文字数を数えます。どうやって数えるかですが、今回はwhileループからwcコマンドに渡して数えました。
wcコマンドの-mオプションは、マルチバイト処理でも文字数を数えてくれます。
しかし最後の改行までカウントしてしまいますね。
$ cat text | tr -d '\n' | gsed 's/ /\n/g' | sed '/^$/d' | while read line; do echo $line | wc -m; done
16
354
104
Q8
マルチーパートなメールデータが読めるか?という問題。
福岡サテライトでは、まずマルチーパートなメールのデータについて解説を行いました。 考えた解答は、出題者上田さんとほぼ同じでした。
Content-Type: multipart/mixed; boundary=047d7b621ee6cf83c604cc276bb3【境界文字列】
--047d7b621ee6cf83c604cc276bb3【境界文字列の頭に--が付いたのがパートの始まり】
Content-Type: text/plain; charset=ISO-2022-JP
Content-Transfer-Encoding: 7bit
....
--047d7b621ee6cf83c604cc276bb3【境界文字列の頭に--が付いたのがパートの始まり】
Content-Type: image/jpeg; name="CHINJYU.JPG"
Content-Disposition: attachment; filename="CHINJYU.JPG"
Content-Transfer-Encoding: base64
X-Attachment-Id: f_h8cn3pxc0
....
--047d7b621ee6cf83c604cc276bb3【境界文字列の頭に--が付いたのがパートの始まり】
Content-Type: image/jpeg; name="IMG_0965.JPG"
Content-Disposition: attachment; filename="IMG_0965.JPG"
Content-Transfer-Encoding: base64
X-Attachment-Id: f_h8cn6ir71
....
H9a0pdUmvWljZ4ysQWFGaBeCFCtj054/DtXPLC3d47kwk56y2If7KW50y8YNBJLBJG1usb53f7JB
xk9On61jS6VNFJqFxdoIZYbWK6QALsnJbBjHYcc4GT2IHJrGhUevkZ1MNypPuf/Z
--047d7b621ee6cf83c604cc276bb3--【境界文字列の前後に--が付くと終了】